
Dans un contexte où les entreprises s’appuient massivement sur leurs données pour piloter leurs activités, la qualité de données devient un enjeu critique. Des données incomplètes, incohérentes ou obsolètes peuvent rapidement fausser les analyses, dégrader l’expérience client et limiter la performance des initiatives digitales, notamment en e-commerce ou en marketing.
Au-delà des impacts opérationnels, une mauvaise qualité de données peut également freiner des projets stratégiques comme l’intelligence artificielle ou la mise en place d’outils décisionnels. Contrairement à la gouvernance des données, qui définit un cadre organisationnel, la data quality relève d’une démarche concrète et opérationnelle : mesurer, contrôler et améliorer en continu la fiabilité des données.
Cet article propose une approche pragmatique pour structurer une démarche de qualité de données, en s’appuyant sur des mécanismes de mesure, des chantiers concrets et des bonnes pratiques directement applicables.
1. Qu’est-ce que la qualité de données (data quality) ?
Gérer la qualité des données, c’est veiller à ce que la donnée soit et reste de qualité. Cela nécessite de mettre en place des processus qui prendront en compte l’inévitable obsolescence de la donnée entrainant la dégradation de l’information.
Un exemple fréquemment évoqué est celui des adresses ; une personne peut très bien changer d’adresse. Interroger un système d’information sur l’adresse de la personne peut renvoyer une réponse fausse si la nouvelle adresse n’est pas renseignée.
Suivant les besoins, la mise à jour de cette adresse sera un enjeu important qui relèvera alors du management de la qualité de données.
2. Qu’est-ce qu’une donnée de qualité ?
2.1. Définition d’une donnée
Une donnée est le couple formé par une définition et une mesure. La mesure étant caractérisée par le type de la donnée :
- Quantitative (poids, montant, âge…)
- Qualitative (nom, ville, date…)
- Technique (code, identifiant…)
Une donnée décrit un état élémentaire du « sujet », « concept » qu’elle renseigne.
2.2. Les critères clés d’une donnée de qualité
On dit qu’une donnée est de (bonne) qualité si elle répond aux trois conditions suivantes :
- Unique : une question amène une seule réponse. L’unicité vise à éviter les doublons, qui sont fréquents dans les bases clients ou produits. Les duplications compliquent les analyses, dégradent l’expérience utilisateur et peuvent entraîner des surcoûts opérationnels.
- Intelligible (ou cohérente) : la réponse est cohérente avec la définition qu’elle renseigne. Il s’agit de vérifier l’absence de contradictions entre différentes sources ou attributs.
- Correcte : la réponse correspond à l’état de la donnée dans le contexte de la question. Cet axe implique la fraîcheur des données : une donnée correcte mais obsolète peut être tout aussi problématique qu’une donnée erronée, notamment dans des contextes temps réel ou marketing.
Ces différentes dimensions constituent un cadre structurant pour évaluer et piloter la qualité des données de manière objective.
3. Pourquoi la qualité de données est un enjeu opérationnel majeur ?
3.1. Coût de la non-qualité de donnée
Le coût de la non-qualité de donnée correspond à l’ensemble des coûts directs ou indirects induits par une mauvaise qualité de la donnée. Etre capable de quantifier ce coût est un enjeu majeur lorsque l’on fait de la qualité de données. En effet, si les coûts directs sont faciles à mesurer (comme le coût de correction de la donnée), les coûts cachés peuvent avoir un impact dévastateur sur l’image d’une entreprise.
3.2. Premier exemple : l’enjeu des NPAI chez un FAI
Pour illustrer cela, prenons l’exemple d’un Fournisseur d’Accès Internet (opérateur réseau). Sa richesse repose, entre autres, sur son parc de clients et sa capacité à les identifier et les cibler. Lors d’un envoi de courrier (ciblage marketing, modification CGU…) la problématique sera de pouvoir localiser ses clients afin de minimiser les NPAI (N’habite Pas à l’Adresse Indiquée) de la base des abonnés :
- En effet, un client peut avoir jusqu’à trois adresses différentes (contact / facturation / raccordement)
- Une étude de l’American Community Suvey estime à 50% le taux de déclaration de changement d’adresse.
Imaginons la séquence suivante :
- L’opérateur notifie, par courrier, ses clients d’un changement tarifaire (via la modification des Conditions Générales de Vente)
- Les clients identifiés en NPAI ne reçoivent pas ledit courrier. Ils ne sont donc pas informés d’une augmentation tarifaire et ne constatent celle-ci que lorsque le prélèvement est effectif sur la facture.
- Si dans la plupart des cas, le client ne réagira peut-être pas, dans certains cas il pourrait y avoir contestation de la facture entrainant un geste commercial opérateur, voire résiliation d’abonnement de la part de clients excédés (on parle alors d’aliénation client)
- Nous pouvons ainsi identifier les différents postes coûts engendrés par les NPAI.
Dans cet exemple, mettre en place un process visant à minimiser le nombre de NPAI de la base client, avant le lancement de la campagne courrier, est une réponse que doit apporter le management de la qualité de données.
3.2. Deuxième exemple : décès & facturation
Si les coûts directs sont plus facilement quantifiables, les coûts cachés peuvent rapidement exploser. Ce fut le cas par exemple pour la chaine de télé Virgin Media. Ayant relancé avec pénalités la facture d’une personne décédée, elle a subi les effets d’un mauvais buzz sur internet. Ce buzz viral, via le relai de la publication de la facture de relance, a entrainé non seulement un remboursement de la facture, des coûts de communication pour calmer le buzz dans les médias ainsi qu’une donation à un hospice, mais aussi une dégradation de l’image de Virgin Media (difficilement quantifiable).
Le client décédé reçoit une facture de relance avec majoration.
L’analyse des flux de paiement bancaires ne prenait visiblement pas tous les cas en compte. Un flux ‘D.D Denied-Payer deceased’ devrait être utilisé pour lancer un process spécifique de mise à jour des données client (et accessoirement de recouvrement de la facture sans pénalité).
Un audit des process de US Postal Services a permis de mesurer que le coût de l’imprécision des données dans les différents entrepôts de données représentait 14,9 millions de dollars (sur 1 milliard de dollars de dépensés à ce jour). Le total est important même si ce montant ne correspond finalement qu’à 1,49% de perte.
Ainsi le coût de la non-qualité de données est une composante primordiale du management de la qualité de données. Il est le garde-fou pour les arbitrages des process d’amélioration de la qualité de données.
4. Comment mesurer et monitorer la qualité des données ?
4.1. Mettre en place des sondes de qualité
La première étape consiste à déployer des règles automatisées permettant de détecter des anomalies dans les données. Ces sondes de qualité peuvent être appliquées directement sur les bases ou dans les flux de données, afin de contrôler des éléments comme la présence de champs obligatoires, la validité de formats ou la cohérence entre attributs.
Par exemple, une sonde peut identifier les fiches produits sans description, les clients sans adresse email valide ou les incohérences entre pays et code postal. Ces contrôles constituent la base d’une démarche de data quality industrialisée.
4.2. Définir des indicateurs de data quality
Les résultats des contrôles doivent être traduits en indicateurs permettant de suivre l’évolution de la qualité dans le temps. Le taux de complétude, le taux de duplication ou encore le taux d’erreurs détectées sont des métriques fréquemment utilisées.
Ces indicateurs permettent non seulement de mesurer l’état des données, mais aussi d’objectiver les progrès réalisés et de piloter les actions d’amélioration.
4.3. Mettre en place un scoring de qualité
Pour aller plus loin, il est pertinent de mettre en place un scoring de qualité de données. Chaque dataset peut être évalué à travers un score global, calculé à partir de plusieurs dimensions comme la complétude ou la cohérence.
Ce scoring permet de hiérarchiser les priorités, d’identifier rapidement les jeux de données critiques et de communiquer plus facilement avec les métiers sur le niveau de qualité.
4.4. Déployer un monitoring et un système d’alerting
Une fois les indicateurs définis, il est essentiel de mettre en place un système de monitoring continu. Des seuils peuvent être définis pour déclencher des alertes en cas de dégradation de la qualité.
Ce mécanisme permet de détecter rapidement les dérives, par exemple lors d’un changement de source ou d’un incident technique, et d’intervenir avant que les impacts ne se propagent dans les usages métiers.
Cela peut se faire via des routines de vérification, des tableaux de bord ou des outils dédiés (ex : Datadog).
5. Les chantiers clés pour améliorer la qualité de données
Plusieurs chantiers typiques peuvent être lancés, mais en premier lieu, nous vous conseillons de mettre une organisation de data governance adaptée.
5.1. Nettoyage et fiabilisation des données
Le nettoyage des données constitue souvent un point de départ indispensable. Il s’agit de corriger les anomalies existantes, notamment en supprimant les doublons, en normalisant les formats et en corrigeant les erreurs les plus fréquentes.
Ce type de chantier permet d’obtenir des gains rapides, mais doit être complété par des actions plus structurantes pour éviter que les problèmes ne réapparaissent.
5.2. Mise en place de référentiels de données
La création de référentiels, notamment pour les données clients ou produits, permet de définir une source de vérité unique. Cela limite les incohérences entre systèmes et améliore la fiabilité globale des données.
Ces démarches s’inscrivent généralement dans des initiatives de master data management et sont particulièrement pertinentes dans des environnements complexes.
5.3. Standardisation des formats et des nomenclatures
La standardisation consiste à définir des règles communes pour les formats, les classifications ou les nomenclatures. Cela facilite l’intégration des données et améliore leur lisibilité.
Sans standardisation, les données deviennent rapidement difficiles à exploiter, notamment lorsqu’elles proviennent de sources multiples.
5.4. Amélioration des processus de collecte
De nombreuses erreurs de données proviennent de la saisie initiale ou des processus de collecte. En intégrant des contrôles dès la création, par exemple dans les formulaires ou les interfaces métiers, il est possible de réduire significativement ces erreurs.
Cette approche permet de traiter le problème à la source, ce qui est beaucoup plus efficace que des corrections a posteriori.
5.5. Fiabilisation des flux de données
La qualité des données dépend également de la fiabilité des flux entre systèmes. La mise en place de contrôles dans les pipelines, la gestion des erreurs et la traçabilité des transformations permettent de sécuriser les échanges et d’éviter la propagation des anomalies.
6. Quels outils pour la data quality ?
La mise en place d’une démarche de qualité de données repose en grande partie sur les outils utilisés pour mesurer, contrôler et améliorer les données. Le marché s’est fortement structuré ces dernières années, avec des solutions couvrant des besoins variés, du simple contrôle de règles jusqu’au monitoring avancé des pipelines de données.
Il est important de comprendre que ces outils ne sont pas cloisonnés : certaines plateformes couvrent plusieurs problématiques (profiling, monitoring, lineage, gouvernance), tandis que d’autres sont plus spécialisées.
En synthèse :
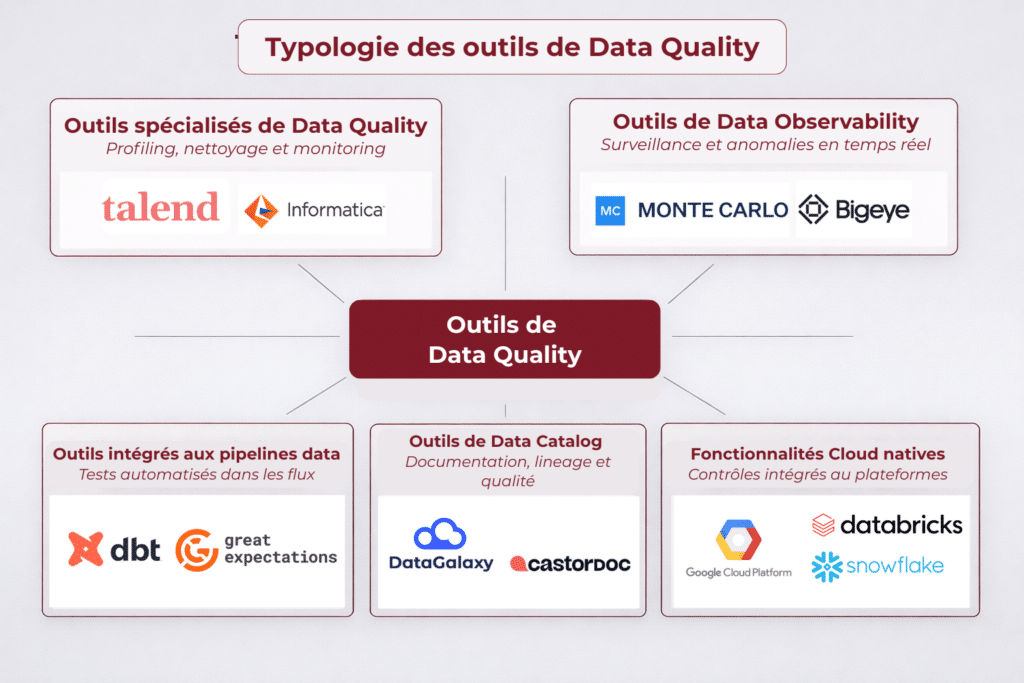
6.1. Outils spécialisés de data quality
Les outils dédiés à la data quality permettent de réaliser des analyses approfondies des données (profiling), de définir des règles de contrôle et d’automatiser les processus de nettoyage.
Des solutions comme Talend Data Quality, Informatica Data Quality ou Ataccama proposent des fonctionnalités avancées telles que :
- l’analyse statistique des données pour détecter des anomalies
- la définition de règles métiers (formats, seuils, cohérences)
- la déduplication et la standardisation
- la mise en place de workflows de correction
Ces outils sont particulièrement adaptés aux organisations ayant des enjeux forts de fiabilité, notamment dans des contextes réglementaires ou à forte volumétrie.
6.2. Outils de data observability et monitoring
Une tendance forte consiste à monitorer la qualité de données en continu, notamment dans les architectures modernes basées sur des pipelines.
Des outils comme Monte Carlo ou Bigeye permettent de détecter automatiquement des anomalies en production, sans nécessairement définir toutes les règles en amont.
Ils reposent sur des approches statistiques ou comportementales pour identifier des dérives, comme une chute soudaine du volume de données ou une variation anormale d’un indicateur.
Ces solutions sont particulièrement utiles dans des environnements data complexes, où les flux sont nombreux et évolutifs.
6.3. Outils intégrés aux pipelines data (data engineering)
Dans les architectures modernes, la qualité de données est de plus en plus intégrée directement dans les pipelines de transformation.
Des outils comme dbt ou Great Expectations permettent de définir des tests directement au niveau des modèles de données.
Ces tests peuvent vérifier des règles simples (non-nullité, unicité) ou des contraintes plus avancées. Ils s’intègrent dans des processus de CI/CD data, ce qui permet de détecter les anomalies en amont, avant même que les données ne soient exploitées.
Cette approche est particulièrement adaptée aux équipes data engineering, dans une logique “data as code”.
6.4. Outils de data catalog et plateformes hybrides
Certains outils de data catalog intègrent désormais des fonctionnalités de qualité de données, en combinant documentation, lineage et monitoring.
Des solutions comme DataGalaxy ou CastorDoc permettent de :
- documenter les jeux de données
- visualiser les flux (lineage)
- associer des indicateurs de qualité
- exposer ces informations aux métiers
Ces plateformes jouent un rôle clé pour rendre la qualité de données visible et compréhensible, au-delà des équipes techniques.
6.5. Fonctionnalités natives des plateformes cloud
Les grandes plateformes cloud proposent également des fonctionnalités intégrées de contrôle de qualité.
Par exemple, des environnements comme Google Cloud Platform, Snowflake ou Databricks permettent de :
- implémenter des contrôles directement dans les pipelines
- monitorer les données via des dashboards
- gérer la qualité à grande échelle
Ces fonctionnalités sont souvent moins spécialisées, mais suffisantes pour couvrir des besoins standards, en particulier dans des architectures cloud natives.
6.6. Vers des outils hybrides et des plateformes unifiées
La frontière entre les différentes catégories d’outils tend à s’estomper. De plus en plus d’acteurs proposent des plateformes combinant :
- data quality
- data catalog
- data lineage
- data governance
Cette convergence répond à un besoin croissant de pilotage global de la donnée, où la qualité n’est plus traitée isolément mais intégrée dans un écosystème plus large.
Le choix des outils dépend donc fortement de la maturité de l’organisation, de son architecture data et des cas d’usage prioritaires.
En conclusion
La qualité de données est un levier essentiel pour garantir la fiabilité des analyses, améliorer l’efficacité opérationnelle et réussir les projets data et IA.
Les organisations qui structurent efficacement leur data quality disposent d’un avantage compétitif durable, en particulier dans des contextes e-commerce et data à forte volumétrie.
Vous souhaitez améliorer la qualité de vos données et structurer une démarche adaptée à vos enjeux ? Contactez-nous pour un accompagnement dédié sur votre gouvernance de données.
Comment mesurer la qualité de données ?
La qualité de données se mesure à l’aide de règles de contrôle (sondes) et d’indicateurs comme le taux de complétude, le taux de duplication ou le taux d’erreurs. Certaines organisations mettent également en place un score de qualité pour suivre l’évolution des données dans le temps.
Comment améliorer la qualité de données ?
Améliorer la qualité de données passe par plusieurs actions : nettoyer les données existantes, mettre en place des contrôles automatisés, standardiser les formats, améliorer les processus de collecte et définir des référentiels fiables pour les données critiques.
Qui est responsable de la qualité de données ?
La qualité de données est une responsabilité partagée entre les équipes métiers, les équipes IT et les rôles data issus des frameworks de data governance (data owner, data steward). Les métiers jouent un rôle clé car ils définissent les exigences et utilisent les données au quotidien.




J’aime bien tous ces éclaircissements sur ces concepts que beaucoup de gens mélangent souvent. Merci!