

 Menu
Menu
Si vous souhaitez d’abord comprendre ce qu’est le Data Mesh et ses origines, notre article de définition pose les bases.
La mise en œuvre d’un environnement Data Mesh exige de repenser les paradigmes traditionnels pour adopter une approche moins centralisée, agile et centrée sur le domaine. Elle repose sur une approche socio-technique où l’organisation humaine prime sur la technologie. La réussite d’un tel projet suit la règle des 80/20. L’organisation devrait consacrer 80 % de l’effort au changement culturel. La technologie ne représente que les 20 % restants.
Le modèle opérationnel du Data Mesh s’appuie largement sur celui des Team Topologies (développé par Matthew Skelton et Manuel Pais) pour définir les structures nécessaires à un flux de valeur rapide et décentralisé.
- La Limitation de la charge cognitive. Selon Skelton et Pais, une équipe n’est performante que si la complexité de sa mission reste dans ses capacités. Dans le Data Mesh, la Plateforme absorbe la complexité technique pour que les équipes métiers se concentrent sur leurs données.
- La Loi de Conway inversée. Cette stratégie consiste à concevoir l’organisation cible pour qu’elle reflète l’architecture logicielle souhaitée. Si l’on veut un système de données décentralisé et modulaire (Mesh), il faut impérativement créer des équipes indépendantes et modulaires.
- L’API d’équipe (Team API). Pour que des équipes autonomes collaborent sans friction, elles doivent formaliser leurs interactions comme un contrat de service, incluant les canaux de communication, la documentation technique et les niveaux de service (SLA) attendus.
Les 4+1 types d’équipes fondamentaux du Data Mesh
Le modèle identifie quatre types d’unités pour structurer la fonction de gestion des données. Cette typologie a d’ailleurs atteint le statut de standard industriel, au point que le framework SAFe (Scaled Agile Framework) l’a intégrée officiellement pour organiser les équipes à grande échelle.
- Équipes de produits de données (Stream-aligned) : Ce sont les unités de base, autonomes et responsables de la livraison de bout en bout d’un produit de données spécifique à un domaine métier. Elles gèrent tout le cycle de vie : ingestion, stockage, conformité et mise à disposition.
- Équipes de plateforme (Platform teams) : Elles fournissent les outils et services techniques « en libre-service » (X-as-a-Service) pour réduire la charge cognitive des équipes produits. Leur but est d’éliminer les frictions opérationnelles en créant un socle technique commun.
- Équipes facilitatrices (Enabling teams) : Composées de spécialistes, elles agissent comme des consultants internes pour aider les autres équipes à surmonter des obstacles techniques ou à adopter de nouvelles compétences (ex. : gouvernance, qualité).
- Équipes de sous-systèmes complexes (Complicated-subsystem teams) : Elles gèrent des parties particulièrement techniques ou spécialisées (ex. : modèles mathématiques lourds, systèmes legacy) que les équipes produits ne pourraient pas assumer seules sans perte d’efficacité.
- Équipes de Gouvernance (Governance teams). Ces équipes ne font pas partie des quatre types d’équipes fondamentaux définis par Matthew Skelton et Manuel Pais. Néanmoins, elles constituent un pilier du modèle opérationnel Data Mesh. Leur mission couvre la cohésion, l’interopérabilité technique et le respect des standards, qu’ils relèvent d’un seul domaine ou concernent l’ensemble de l’organisation.
Composition d’une équipe « Produit de Données »
Une équipe type est généralement petite (maximum 7 à 9 personnes, suivant la « Two-Pizza Rule » chère à Jeff Bezos) et comprend des rôles clés :
- Le Data Product Owner (DPO). Il agit comme le « CEO » du produit de données. Il définit la vision, priorise le backlog et est responsable du succès commercial et technique du produit. Il doit posséder un équilibre entre acuité commerciale, sens financier et compétences techniques profondes. Dans certaines structures, la compétence technique repose sur un rôle spécifique. Un leader technique (Technical Leader) garantit alors la qualité et la fiabilité des produits.
- Les ingénieurs spécialisés. L’équipe réunit quatre grandes compétences : ingénierie de métadonnées (catalogue, contrats de données), sécurité (GDPR), ingestion (pipelines, APIs) et gestion des releases pour coordonner les déploiements.
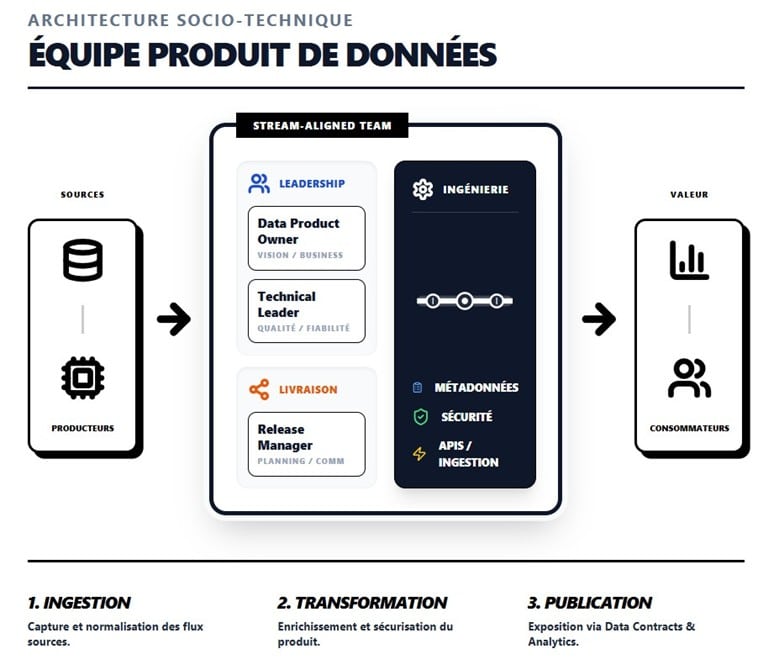
La composition de l’équipe doit être stable dans le temps, car la construction de relations de confiance s’inscrit dans la durée.
Modes d’interaction entre équipes
Dans un Data Mesh, la structure des équipes ne suffit pas. Les modes d’interaction entre elles sont tout aussi déterminants pour garantir un flux de valeur rapide et limiter la charge cognitive.
- X-as-a-Service (XaaS). C’est certainement le mode à privilégier pour maximiser l’autonomie et le flux de livraison. Une équipe fournit un service (API, outil, produit) qu’une autre consomme avec un minimum d’interaction directe. Dans le Data Mesh, c’est l’interaction type entre l’équipe plateforme et les équipes produits, ces dernières utilisant les outils en libre-service pour éviter de « réinventer la roue ».
- Collaboration. Deux équipes travaillent étroitement sur un objectif commun, partageant la responsabilité des résultats. Si ce mode favorise l’innovation et la découverte, il est coûteux en termes de productivité et de communication interne. Dans la mesure du possible, il faut limiter la collaboration à des périodes définies.
- Facilitation. Ce mode est l’essence même des équipes facilitatrices (Enabling teams). L’objectif est qu’une équipe d’experts aide une équipe produit à résoudre un problème spécifique ou à acquérir une nouvelle compétence afin de la rendre la plus autonome possible.
Le continuum du modèle opérationnel
Le concept s’applique directement aux équipes 4+1. Les organisations se situent sur un spectre allant de la centralisation totale à la distribution complète, chaque étape modifiant la répartition de ces équipes.
1. Le modèle centralisé
Dans ce modèle, les capacités sont regroupées. L’équipe de plateforme, les équipes facilitatrices et l’équipe de gouvernance sont souvent fusionnées au sein d’une direction informatique centrale. Toutes les compétences sont concentrées au sein de l’IT. Les métiers n’ont pas d’équipes propres et dépendent entièrement de la direction informatique.
- Avantage : Économies d’échelle et standards uniformes.
- Risque : Goulot d’étranglement et manque de réactivité métier.
2. Le modèle distribué
Ici, la décentralisation est maximale, ce qui peut mener à une fragmentation. Chaque domaine métier possède non seulement ses équipes produits, mais aussi ses propres experts (équipes facilitatrices) et parfois même sa propre déclinaison de la plateforme technique. La gouvernance suit le même schéma : chaque domaine définit ses propres politiques et standards, souvent sans concertation globale.
- Avantage : Autonomie totale et vitesse locale maximale.
- Risque : L’émergence de silos technologiques dans lesquels chaque domaine utilise des outils, des pratiques et des normes spécifiques. L’existence de ces silos se manifeste par une duplication massive des coûts (licences redondantes, infrastructures multiples), une fragmentation de la donnée (avec des définitions contradictoires) et une absence d’interopérabilité entre domaines.
3. Le modèle fédéré (cible privilégiée du Data Mesh)
C’est l’équilibre recherché, où l’autonomie est balancée par une interopérabilité globale. C’est la solution qui permet de concilier les avantages des deux modèles précédents tout en en limitant les risques.
- Les équipes produits (Stream-aligned) sont distribuées dans les domaines métiers pour la pertinence business.
- L’équipe de plateforme reste centralisée pour fournir des outils communs « en libre-service ».
- L’équipe de gouvernance (+1) devient fédérée : elle n’est plus une tour d’ivoire, mais un conseil composé de représentants des domaines et de la plateforme qui s’accordent sur des politiques et des standards partagés.
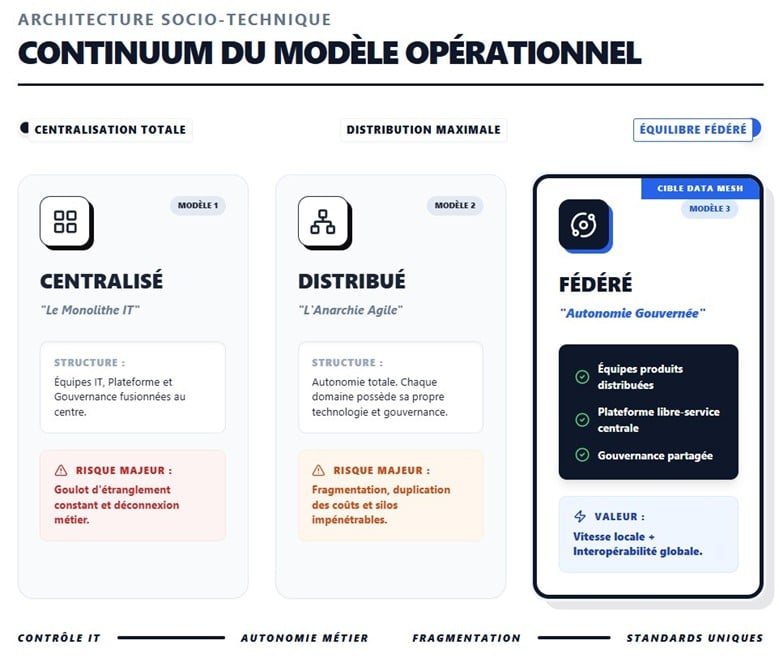
La stratégie de décentralisation vers un modèle fédéré
Décentraliser de manière partielle et incrémentale
Plusieurs stratégies intermédiaires permettent d’avancer vers le modèle fédéré sans décentraliser d’un coup. Elles reposent sur trois critères principaux :
- Le niveau de sensibilité des données. Si une donnée présente un risque réglementaire ou de sécurité trop élevé pour être gérée par les équipes métier en raison de leur manque de compétences sur ces problématiques, elle reste souvent sous la responsabilité centralisée de l’équipe informatique.
- La portée des données (Master Data vs Domain Data). Les données partagées par toute l’organisation (Clients, Produits, Référentiels) nécessitent des outils communs pour garantir une cohérence transverse. À l’inverse, les données transactionnelles spécifiques à un domaine/processus sont les candidates idéales pour être prises en charge rapidement par les acteurs métier.
- Le niveau d’enrichissement. La plupart du temps, l’IT conserve la gestion de l’approvisionnement en données issues des systèmes legacy (produits source-aligned) dont elle maîtrise la complexité, tandis que les domaines métiers prennent la main sur des produits de données transformés (Consumer-aligned) pour répondre à leurs besoins spécifiques.
Développer les capacités de base avant de distribuer les redevabilités
Les données peuvent être gérées comme des produits sans qu’il soit nécessaire de décentraliser les responsabilités vers les domaines métier. En revanche, l’inverse n’est pas vrai. Pour décentraliser durablement la gestion des données sans créer de silos incapables d’interagir, il est indispensable d’adopter une approche « data as a product ».
La mise en place d’un catalogue de données est un prérequis concret à cette étape nos recommandations sur les paliers d’adoption détaillent comment progresser.
La décentralisation doit donc intervenir soit en parallèle de cette adoption, soit ultérieurement. Cette démarche pose un socle technique et méthodologique solide. Elle limite dans un premier temps les transformations organisationnelles liées à la redistribution des responsabilités.
Pour aller plus loin sur le sujet, consultez notre offre d’accompagnement sur la gestion et la gouvernance des données ou à nous contacter directement.


